Programación modular 2
1 Programación estructurada 2
1.1 Procedimientos y funciones 2
1.1.1 Funciones 3
1.1.2 Procedimientos 4
1.2 Parámetros de un procedimiento o función 4
1.2.1 Parámetros de entrada 5
1.2.2 Parámetros de salida 6
1.2.3 Parámetros de entrada/salida 7
1.3 Descomposición de una tarea en procedimientos y
funciones 8
1.4 Cuestiones de ámbito 10
1.5 Ámbito de un procedimiento o función 10
1.6 Ámbito de variables 10
1.7 Variables locales y globales 11
1.8 Efectos laterales 13
1.9 Precedencia del nombre 15
1.10 Cuestiones de implantación 16
1.10.1 Proceso de invocación de un procedimiento o
función 16
1.10.2 Mecanismos de paso de parámetros en los
lenguajes de programación 17
1.10.3 Paso de parámetros por valor 17
1.10.4 Paso de parámetros por referencia 17
2 Programación modular 17
2.1 Módulos de mayor nivel 20
3 Traducción de pseudocódigo a jC 22
3.1 Paso por valor y paso por referencia en jC 22
3.1.1 Paso por valor 22
3.1.2 Paso por referencia 22
3.2 Funciones y procedimientos 23
3.3 Manejo de módulos 25
4 Ejercicio resuelto 26
5 Ejercicios 29
Programación
modular
A medida que avanza el tiempo, los
problemas que se espera que un computador resuelva se vuelven más
y
más complejos. Así, es en realidad muy extraño que
se pueda
diseñar un algoritmo simple que resuelva un problema real hoy en
día, por lo que es necesario plantearse algún tipo de
subdivisón
que haga el problema abordable, en subproblemas manejables.
En este tema se presentan las
herramientas de programación que permiten resolver problemas
complejos mediante su descomposición en otros más simples.
1Programación estructurada
Es este paradigma de programación el que se
podría
llamar “original”, procedimental, o también conocido como
“Divide y vencerás”. Se trata de dividir el problema a resolver
en tareas a realizar, y estas tareas en una serie de procedimientos,
para finalmente encontrar el algoritmo que mejor se encuadre en
ellos.
Fortran (creado en 1954, por Jhon Backus) es el
lenguaje original de programación procedimental, aunque hoy en
día
la mayoría de los lenguajes de programación la permiten.
El
lenguaje Pascal (de principios de los 70, creado por Niklaus Wirth),
es muy conocido debido al refuerzo que hacía de este tipo de
programación.
En este tipo de programación, el programador debe
concentrarse en que cada procedimento tenga una interfaz consistente,
describiendo los argumentos de entrada y los de salida, y que cada
procedimiento sea independiente del resto.
1.1Procedimientos y funciones
Un algoritmo que resolviera un
problema complejo, contendría cientos o miles de líneas de
código
en su interior. Esto es inabarcable para cualquier programador, por
lo que se utiliza el concepto de procedimientos y funciones para
subdidivir el problema en partes. La idea es que cada una de estas
partes contenga un conjunto de instrucciones que permita la
ejecución
de algún proceso determinado y lógico desde el punto de
vista
humano.
Dos ejemplos, función y
procedimiento respectivamente:
FUNCION multiplicar(E a:
ENTERO, E b: ENTERO): ENTERO
multiplicar ←
( a * b )
FIN_FUNCION
ó
PROCEDIMIENTO escribirEdad(E
mensaje: CADENA, E edad: ENTERO)
ESCRIBIR( mensaje, edad )
FIN_PROCEDIMIENTO
La descomposición del software en
tareas también se conoce con el nombre de top-down y fue
presentada
por primera vez por Niklaus Wirth. Este autor proporciona la
siguiente visión de refinamiento:
“En cada paso (del
refinamiento), una o varias instrucciones del programa dado, se
descomponen en instrucciones más detalladas. Esta
descomposición
sucesiva o refinamiento de especificaciones termina cuando todas las
instrucciones están expresadas en términos de la
computadora
usada o del lenguaje de programación… Conforme se refinan las
tareas, también los datos pueden ser refinados, descompuestos o
estructurados siendo natural refinar las especificaciones del
programa y los datos en paralelo
Cada paso de refinamiento implica
algunas decisiones de diseño. Es importante que el programador
sea
consciente de los criterios subyacentes (en las decisiones de
diseño
adoptadas) y de la existencia de soluciones alternativas…”
Típicamente, una descomposición insuficiente
de un
problema en tareas conduce a la definición de pocos
procedimientos,
cada uno de las cuales implementará múltiples
funcionalidades.
1.1.1Funciones
Una función es una un conjunto de
instrucciones, con un nombre asociado, que cumple las siguientes
características:
-
Tiene uno o más
parámetros de entrada.
-
Tiene un parámetro
exclusivamente de salida y de tipo simple (es decir, lo que
devuelve). Muchos lenguajes de programación no requieren el
hecho de que el parámetro sea simple pero en esta asignatura
se considerará la versión más purista.
-
Todos los valores de entrada son
necesarios y suficientes para determinar el valor de salida.
Su sintaxis es la siguiente:
FUNCION nombreFuncion(lista de
parámetros formales): Tipo_de_salida
CONSTANTES
...
TIPOS
...
VARIABLES
...
INICIO
instrucción 1
instrucción 2
....
return
expresión { de Tipo_de_salida }
FIN_FUNCIÓN
A continuación se muestra, como
ejemplo, una función que devuelve la mayor de dos variables.
FUNCION max (E a: ENTERO,
E b: ENTERO): ENTERO
VARIABLES
valorDeRetorno: ENTERO
INICIO
SI a > b
valorDeRetorno ←
a
SINO
valorDeRetorno ←
b
FINSI
max ←
valorDeRetorno
FIN_FUNCIÓN
1.1.2Procedimientos
Son conjuntos de instrucciones con un
nombre asociado, al igual que las funciones, pero no devuelven
ningún
valor. Los parámetros pueden ser de entrada, salida o de entrada
/
salida.
Su sintaxis es la siguiente:
PROCEDIMIENTO
nombre_procedimiento(lista_de_parámetros_formales)
CONSTANTES
...
TIPOS
...
VARIABLES
...
INICIO
instrucción 1
instrucción 2
....
FIN_PROCEDIMIENTO
Al no soportar el retorno, al
contrario que las funciones, para devolver valores se usan
parámetros
de salida o de entrada/salida.
1.2Parámetros de
un procedimiento o función
Los parámetros o argumentos de una
función o procedimiento son el mecanismo que permite el
intercambio
de datos entre la función o procedimiento que es llamado y el que
realiza la llamada.
En el momento de definir una
función
o procedimiento, es necesario especificar los parámetros, con el
tipo asociado. En este momento, los parámetros se denominan
formales.
Por otra parte, en el momento de
hacer la llamada a una función o procedimiento, cuando se
utilizan
literales o variables como lista de parámetros (que deben
emparejarse con los parámetros formales en cuanto al tipo y
orden).
Estos parámetros se denominan reales.
ALGORITMO Mayor
{ a y b son parámetros formales de la
función max }
FUNCION max (E a: ENTERO,
E b: ENTERO): ENTERO
VARIABLES
valorDeRetorno: ENTERO
INICIO
SI a > b
valorDeRetorno ←
a
SINO
valorDeRetorno ←
b
FINSI
max
←
valorDeRetorno
FIN_FUNCIÓN
VARIABLES
num1,
num2, mayor: ENTERO
INICIO
LEER( num1 )
LEER( num2 )
mayor ←
max( num1 , num2 ) { num1 y num2 son parámetros reales }
ESCRIBIR( mayor )
FIM_ALGORITMO
1.2.1Parámetros
de entrada
Permiten aportar datos a función o
procedimiento por parte del algoritmo que le invoca. Un parámetro
real asociado con un parámetro formal de entrada, puede ser un
literal, una variable o incluso el valor que se obtendrá como
resultado de la evaluación de una expresión. La
definición de un
parámetro formal de entrada se hace anteponiendo el modificador E
delante del nombre del parámetro formal.
Ejemplo:
ALGORITMO Ejemplo
CONSTANTES
Max: ENTERO = 50
TIPOS
Vector = ARRAY [Max] DE
ENTERO
VARIABLES
a: Vector
numElem: ENTERO
{visualiza los elementos de un vector
Parámetros:
v: vector de entrada
n: número de elementos a visualizar
}
PROCEDIMIENTO escribirVector(E
v: Vector, E n: ENTERO)
VARIABLES
i: ENTERO
INICIO
DESDE i ←
0 HASTA n - 1
ESCRIBIR( v[ i ] );
FIN_DESDE
FIN_PROCEDIMIENTO
{Invocación }
INICIO
...
escribirVector( a, Max )
escribirVector( a, 5 )
numElem ←
( Max / 10 ) * 5
escribirVector( a, ( Max / 10 ) * 5 )
escribirVector( a, numElem )
...
FIN_ALGORITMO
Modificando un parámetro formal de
entrada nunca se modifica el correspondiente parámetro
real.
Es decir, en la cuarta llamada ( escribirVector( a, numElem )
), aunque se modificara n dentro del procedimiento
escribirVector(), esa modificación nunca se
repercutiría en
numElem.
1.2.2Parámetros
de salida
Permiten que la acción pueda
devolver resultados de su ejecución al algoritmo que invoca. El
parámetro real asociado con un parámetro formal de este
tipo debe
ser necesariamente una variable en la que almacenar el resultado
devuelto por la acción. Esa variable no tiene porque haber sido
inicializada con anterioridad.
Cualquier acción o
modificación
realizada sobre el parámetro formal de salida se refleja, de
forma
inmediata, sobre el correspondiente parámetro real. Para la
definición de un parámetro formal de salida se debe
anteponer el
modificador S delante del nombre formal.
Ejemplo:
ALGORITMO VerSecuenciaDeNumeros
CONSTANTES
Max: ENTERO = 50
TIPOS
Vector = ARRAY [Max] DE
ENTERO
{lee los datos de un vector
Datos de Entrada: No tiene
Datos de salida: vector leído y el
número de elementos leído
}
PROCEDIMIENTO leerVector (S v:
Vector, S n: ENTERO)
VARIABLES
i: ENTERO
INICIO
{ Leer el número máximo de
elementos }
REPETIR
LEER( n )
HASTA ( n > 0 Y n < Max
)
{ Leer los elementos del vector }
DESDE i
0 HASTA n - 1 HACER
LEER ( v[ i ] )
FIN_DESDE
FIN_PROCEDIMIENTO
{visualiza los elementos de un vector
Parámetros:
v: vector de entrada
n: número de elementos a visualizar
}
PROCEDIMIENTO escribirVector(E
v: Vector, E n: ENTERO)
VARIABLES
i: ENTERO
INICIO
DESDE i ←
0 HASTA n - 1
ESCRIBIR( v[ i ] );
FIN_DESDE
FIN_PROCEDIMIENTO
VARIABLES
v1: Vector
numElem: ENTERO
INICIO
leerVector( v1, numElem )
escribirVector( v1, numElem ) { v1 y
numElem tienen ya valores }
FIN_ALGORITMO
1.2.3Parámetros
de entrada/salida
Los parámetros de entrada/salida
permiten aportar datos de entrada en un procedimiento o función,
que
ésta los modifique y los devuelva como resultado al algoritmo que
la
invoca. El parámetro real asociado con un parámetro formal
declarado de entrada /salida, necesariamente debe ser una variable
donde almacenar el valor devuelto por el procedimiento o función
invocada y debe haber sido inicializado previamente a la
invocación.
La declaración de un parámetro de entrada/salida se
hará
anteponiendo el modificador E/S delante del nombre del
parámetro formal en la definición de la función.
En el siguiente ejemplo se muestra
un algoritmo que permite intercambiar dos posiciones cualesquiera del
vector.
ALGORITMO IntercambiarEnVector
CONSTANTES
Max: ENTERO = 50
TIPOS
Vector = ARRAY [Max] DE
ENTERO
{lee los datos de un vector
Datos de Entrada: No tiene
Datos de salida: vector leído y el
número de elementos leído
}
PROCEDIMIENTO leerVector (S v:
Vector, S n: ENTERO)
VARIABLES
i: ENTERO
INICIO
{ Leer el número máximo de
elementos }
REPETIR
LEER( n )
HASTA ( ( n > 0 )
Y ( n < Max ) )
{ Leer los elementos del vector }
DESDE i ←
0 HASTA n - 1 HACER
LEER ( v[ i ] )
FIN_DESDE
FIN_PROCEDIMIENTO
PROCEDIMIENTO intercambiar (E/S
v: Vector, E a, b: ENTERO, E n: ENTERO)
VARIABLES
aux: ENTERO
INICIO
SI ( ( a <= n )
Y ( a >= 0 )
Y ( b >= 0 )
Y ( b <= n ) )
aux
←
v[ b ]
v[ b ] ← v[ a ]
v[ a ] ← aux
FIN_SI
FIN_PROCEDIMIENTO
{visualiza los elementos de un vector
Parámetros:
v: vector de entrada
n: número de elementos a visualizar
}
PROCEDIMIENTO escribirVector(E
v: Vector, E n: ENTERO)
VARIABLES
i: ENTERO
INICIO
DESDE i ←
0 HASTA n - 1
ESCRIBIR( v[ i ] );
FIN_DESDE
FIN_PROCEDIMIENTO
VARIABLES
v1: Vector
n: ENTERO
INICIO
leerVector( v1, n )
SI ( n > 5 )
intercambiar( v1, 2, 5, n )
FIN_SI
escribirVector( v1, n )
FIN_ALGORITMO
1.3Descomposición de una tarea en procedimientos
y funciones
La mayor complejidad a la hora de
aplicar programación estructurada es saber decidir correctamente
cuándo extraer código para colocarlo en un procedimiento o
función,
y cuándo utilizar una u otra.
Siguiendo el algoritmo mostrado en
la sección anterior, veamos la subdivisón adecuada en
procedimientos y funciones del siguiente problema: leer un vector,
intercambiar el contenido de las posiciones 2 y 5 y mostrarlo por
pantalla.
E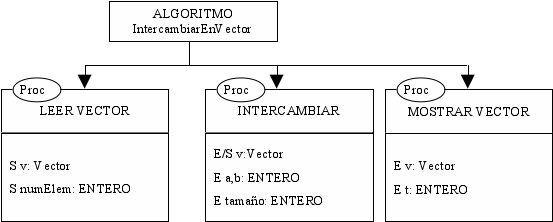
l
proceso de identificación de procedimientos y funciones se basa
en
el empleo de cuestiones lógicas (experiencia y sentido
común),
ciertas heurísticas y una regla básica: “Existen
procedimientos y
funciones que realizan procesos de entrada de datos, otras de salida
de datos y otras de procesamiento de datos. Un procedimiento o
función no debe combinar los tres tipos de tareas.”
Entre las heurísticas a tener en
cuenta se encuentran las siguientes:
-
Cada vez que se necesita operar con
ciertos tipos de datos compuestos (como registros o vectores) suele
resultar necesario disponer de procedimientos para la lectura de
esos datos, otras para la visualización de los mismos y
finalmente otras que implementen las distintas operaciones
necesarias.
-
Las operaciones de
inicialización de un algoritmo que se ejecutan antes de
empezar a funcionar dicho algoritmo (lecturas de ficheros de disco,
inicialización de estructuras de datos) se colocan
normalmente en un procedimiento (muchas veces llamado iniciar)
si bien, de resultar ser este procedimiento demasiado extenso o
complejo, se puede subdividir, a su vez, en otros procedimientos.
Esto mismo ocurre con las operaciones que se deben ejecutar justo
antes de terminar el algoritmo (volcados a disco, etc.). Por otra
parte, si las operaciones son muy sencillas, no será
probablemente interesante realizar este proceso.
-
Las operaciones de búsqueda y
ordenación en cualquier estructura de datos se
implementarán normalmente en procedimientos.
-
Cada una de las funcionalidades que un
algoritmo proporcionará a un usuario es un procedimiento.
Tomando el enunciado del problema, muchas veces se pueden
identificar los procedimientos (de más alto nivel) a crear
prestando atención a los verbos presentes.
-
Un indicativo de que un procedimiento
o función es demasiado grande suele ser el número de
líneas que ocupa: si contiene más de 25 – 30
líneas (no se visualizará totalmente en una sola
pantalla) es demasiado grande y, por lo tanto, debe ser
descompuesta, a su vez, en procedimientos o funciones más
pequeños.
-
Cuando en un algoritmo se repita
más de una vez la misma tarea con una diferencia
pequeña, esta diferencia pequeña se
representará en los parámetros de un procedimiento o
función que será capaz de adaptarse a todas las
circunstancias en las que pueda ser empleado. En todo caso, hablar
de diferencia pequeña implica que las instrucciones
ejecutadas son las mismas y que, por ejemplo la única
diferencia se encuentra en el número de veces que se ejecuta
una composición iterativa o cuestiones muy similares que se
puedan parametrizar. Un error muy común es emplear un
procedimiento para dos acciones totalmente diferentes empleando un
parámetro que indique cuál de ellas ejecutar.
-
La interfaz de un procedimiento o
función se diseñará para asegurar la
máxima reutilización.
1.4Cuestiones de ámbito
En este apartado se tratarán una
serie de cuestiones adicionales a tener en cuenta cuando se habla de
procedimientos y funciones, que engloban conceptos relacionados con
el ámbito de variables, los efectos colaterales, etc...
1.5Ámbito de un
procedimiento o función
En general, se entiende por ámbito
de un procedimiento o función M, el conjunto de otras funciones o
procedimientos que pueden invocarla.
1.6Ámbito de
variables
Las variables sólo se pueden
referenciar desde la función o procedimiento en la que
están
declaradas. Así, es fundamental restringir el uso de variables a
las
funciones o procedimientos en las que están declaradas para no
sufrir errores de programación debida a efectos laterales.
El ámbito de una variable local o
parámetro formal v declarada dentro de una función o
procedimiento
M es la propia función o procedimiento, cuyas instrucciones
pueden
modificarla o consultarla.
A veces, ésto puede complicarse
debido a que ciertos lenguajes de programación, como Pascal,
permiten crear funciones (locales) dentro de funciones, de manera que
las variables locales y parámetros formales creados para la
contenedora sirven para todas las locales. Otros lenguajes, como C++,
permiten crear bloques dentro de funciones o procedimientos, de
manera que las variables creadas dentro de ellos tienen como
ámbito
sólo el bloque mencionado, y sin embargo se puede acceder al
resto
de variables de la función. Por ejemplo:
int elevarA(int
x, int y)
{
int toret = 1;
{
/*
n sólo tiene vida dentro de este bloque
sin embargo, se puede acceder a x e y
*/
int n;
for(n = 0; n < y; ++n) {
toret = toret * x;
}
}
return toret;
}
Una función o procedimiento debe
usar únicamente para su funcionamiento:
De esta manera, se evitarán
efectos
laterales con variables globales, como se discute a continuación.
1.7Variables
locales y globales
Las variables que aparecen en un
algoritmo o programa se dividen atendiendo a su ámbito en locales
y
globales.
-
Variables locales: son aquellas
cuyo ámbito de actuación se reduce a la función
o procedimiento donde están definidas. Fuera de su
función o procedimiento, estas variables no serán
conocidas.
-
Variables globales: son
aquellas definidas por el algoritmo o programa principal, y
potencialmente, su ámbito de actuación se extiende a
todas los procedimientos y funciones del algoritmo, siempre que no
se hayan (re)definido en el interior de alguna de ellas, bien
variables locales o bien como parámetros, con el mismo
identificador.
El intercambio de información
entre
procedimientos y funciones debe producirse siempre a través de
los
parámetros y nunca a través de variables globales.
Cualquier otro
dato cuyo uso sólo tenga sentido dentro de una función o
procedimiento, se declarará como una variable local a
ésta,
incluso en el caso de que una variable similar con el mismo
identificador y tipo se use en otros procedimientos y funciones.
Tal y como se ha comentado con
respecto a las variables globales, una variable local de una
función
o procedimiento oculta a la variable global con el mismo
identificador, tal y como se ve en el ejemplo más abajo:
ALGORITMO ocultación
VARIABLES
x,
y: ENTERO
FUNCION elevarA(x:
ENTERO, y: ENTERO):
ENTERO
VARIABLES
resultado:
ENTERO
INICIO
resultado ←
1;
DESDE i ←
0 HASTA y - 1
resultado ←
resultado * x
FIN_DESDE
elevarA ←
resultado;
FIN_FUNCION
INICIO
LEER( x )
LEER( y )
ESCRIBIR( “x^y = “, elevarA( x, y ) )
FIN_ALGORITMO
En este ejemplo, la variable local
'x' oculta, dentro de la función elevarA(), a la variable
x
del algoritmo principal.
Una cuestión adicional es que, en
la mayoría de lenguajes de programación, incluyendo a jC,
existe un punto de entrada al programa que es una función con un
nombre determinado, en el caso de estos lenguajes, main(). Es
posible elegir si las variables del algoritmo principal serán
variables globales o locales de esta función. Así, es
posible
implementar el anterior algoritmo sin que se produzca esta
ocultación. La traducción directa a jC se muestra a
continuación.
/**
@name ElevaOcultacion
@brief Eleva base a exponente (con
ocultación)
@author jbgarcia@uvigo.es
*/
import std.io;
import
std.util;
int
x = 0;
int
y = 0;
/** Devuelve x^y
@param x La base
@param y El exponente
@return
x^y, como entero
*/
int elevarA(int
x, int y)
{
int toret = 1;
int n;
for(n = 0; n < y; ++n) {
toret = toret * x;
}
return toret;
}
int main()
{
int
resultado;
x = strToInt( readln( “Introduzca base: “
) );
y = strToInt( readln( “Introduzca
exponente: “ ) );
printf( “%d\n”, elevarA( x, y ) );
return ExitSuccess;
}
/**
@name ElevaOcultacion2
@brief Eleva base a exponente (con
ocultación)
@author jbgarcia@uvigo.es
*/
import
std.io;
import
std.util;
import std.string;
/** Devuelve x^y
@param x La base
@param y El exponente
@return x^y como entero
*/
int elevarA(int
x, int y)
{
int toret = 1;
int n;
for(n = 0; n < y; ++n) {
toret = toret * x;
}
return toret;
}
int main()
{
int
x = strToInt( readln( “Introduzca base: “ ) );
int
y = strToInt( readln( “Introduzca exponente: “ ) );
println( elevarA( x, y ) );
return ExitSuccess;
}
De esta manera, es posible escribir
un programa sin utilizar ni una sola variable global (que es lo
más
aconsejable). Dado que las variables locales se almacenan en el
interior de la propia función o procedimiento, sólo
deberemos
declarar como globales aquellas variables, como estructuras o
matrices, de gran tamaño, que no caben en la pila( stack).
Los
detalles internos, que explican este problema, se detallan en la
siguiente sección sobre cuestiones de implementación.
1.8Efectos laterales
Efecto lateral es cualquier
modificación de una variable producida en un procedimiento o
función
en la que la variable no está declarada. Estos efectos deben
evitarse pues introducen dependencias indeseables (la función o
procedimiento depende entonces de una variable global, por ejemplo),
que son causas de errores muy difíciles de detectar. En el
siguiente
algoritmo, la salida es “Falso”, tal y como se pretendía, pero
no se visualiza nada más, cuando se pretendía avisar de
que el
número era negativo.
ALGORITMO efectosLaterales
VARIABLES
a: ENTERO
PROCEDIMIENTO proc (E p:
ENTERO)
INICIO
a ←
abs( a ) { en este punto se produce un efecto lateral }
SI ( p > a )
ESCRIBIR( “Cierto” )
SINO
ESCRIBIR( “Falso” )
FIN_SI
FIN_PROCEDIMIENTO
INICIO
a ←
-3
proc( 2 )
SI ( a < 0 )
ESCRIBIR( “Aunque 'a' era negativo
...” ) { ... nunca se ejecuta }
FIN_SI
FIN_ALGORITMO
La corrección del efecto lateral se
puede obtener con una simple modificación del código, que
no
modifique 'a'. Ahora, el resultado es el esperado.
ALGORITMO efectosLaterales
VARIABLES
a: ENTERO
PROCEDIMIENTO proc (E p:
ENTERO)
INICIO
SI ( p > abs( a ) ) { en
este punto se producía un efecto lateral }
ESCRIBIR( “Cierto” )
SINO
ESCRIBIR( “Falso” )
FIN_SI
FIN_PROCEDIMIENTO
INICIO
a ←
-3
proc( 2 )
SI ( a < 0 )
ESCRIBIR( “Aunque 'a' era negativo
...” )
FIN_SI
FIN_ALGORITMO
Sin embargo, a pesar de que con esta
modificación se corrige el efecto lateral, el algoritmo sigue
sufriendo del mismo problema que lo causó: el procedimiento proc()
que no sólo utiliza sus parámetros y variables locales
para
trabajar, sino que confía en la existencia de una variable global
a.
Podemos corregir fácilmente este problema con un nuevo
parámetro, e
incluso dejar el algoritmo tal y como estaba en un principio.
ALGORITMO efectosLaterales
VARIABLES
a: ENTERO
PROCEDIMIENTO proc (E p:
ENTERO, E a:
ENTERO)
INICIO
a ←
abs( a )
SI ( p > a )
ESCRIBIR( “Cierto” )
SINO
ESCRIBIR( “Falso” )
FIN_SI
FIN_PROCEDIMIENTO
INICIO
a ←
-3
proc( 2, a )
SI
( a < 0 )
ESCRIBIR( “Aunque 'a' era negativo
...” )
FIN_SI
FIN_ALGORITMO
1.9Precedencia
del nombre
En un algoritmo pueden definirse
identificadores de variables idénticos siempre y cuando se
definen
en procedimientos o funciones distintas.
Cuando se ejecuta una instrucción
y
se puede recuperar el valor de varias variables con el mismo nombre,
se presenta un conflicto de ambigüedad que se resuelve mediante el
criterio conocido como “precedencia del nombre”. Este criterio
implica que se coge la variable definida en la función o
procedimiento más cercano usando el criterio de ámbito de
la
variable en cuestión. Así, tiene preferencia, como ya se
ha visto,
la variable con el ámbito más cercano o más local.
Como ejemplo,
se muestra un pequeño algoritmo que utiliza un procedimiento con
variables de entrada y de salida para ejemplificar lo visto hasta
ahora. La salida del algoritmo se muestra a continuación.
-
ALGORITMO precedenciaDeNombre
VARIABLES
a, b: ENTERO
PROCEDIMIENTO proc(E a:
ENTERO; S b: ENTERO)
INICIO
b ←
25
a ←
b + 5
FIN_PROCEDIMIENTO
INICIO
a
←
1
b ←
1
ESCRIBIR( a, b )
proc( 1, a )
ESCRIBIR( a, b )
FIN_ALGORITMO
1.10Cuestiones de implantación
Se
han
descrito los comportamientos de los mecanismos de paso de
parámetros, llamada a funciones o procedimientos ... En esta
sección
se describe qué sucede realmente, a nivel de sistema operativo,
cuando estos mecanismos se activan.
1.10.1Proceso de invocación de un procedimiento
o función
Al ejecutar un programa, el sistema
operativo asigna cierta cantidad de memoria al mismo. El programa en
ejecución (proceso en memoria) organiza el espacio asignado
atendiendo al siguiente esquema:
-
TEXT es la zona de la memoria
donde se almacenan las instrucciones del programa. Muchas veces, en
TEXT se almacenan también las constantes, al ser esta zona
de
la memoria normalmente de sólo lectura. En DATA se
almacenan
las variables globales (no las constantes). El STACK (o pila
de llamadas) permite al sistema operativo seguir el flujo de
ejecución del programa. Finalmente, el HEAP es una zona
ampliable de la memoria donde se almacenan estructuras de datos que
pueden variar de tamaño con el tiempo.
Cuando aparece una llamada a una
función o procedimiento M, se crea en la pila (stack) un
registro de activación o entorno de ejecución, denominado
marco o
frame de la pila, en donde se alojan las variables locales y
parámetros formales declarados en la función o
procedimiento, así
como, la dirección de retorno a la instrucción posterior a
la
invocación.
Una vez creado el entorno, se cede
el control a la primera instrucción de M. Si M llama a otra
función
o procedimiento M', se creará un nuevo frame en la pila, y se
procede a la primera instrucción de M'. De este modo se pueden ir
apilando llamadas (de ahí, su nombre) mientras sea necesario.
Finalmente, cuando la ejecución
del
procedimiento o función M' involucrado se completa, se destruye
su
marco en la pila, se recupera el marco anterior, correspondiente a M
(la que hizo la invocación), y se establece el contador de
programa
a la dirección de retorno del marco eliminado.
1.10.2Mecanismos de paso de parámetros en los
lenguajes de programación
Los mecanismos descritos aquí, de
paso de parámetros de entrada, salida y entrada/salida, no suelen
encontrarse en los lenguajes de programación, por el contrario,
lo
más típico es encontrar mecanismos de paso por valor y
paso por
referencia.
1.10.3Paso de parámetros por valor
Cuando se realiza la llamada de un
procedimiento o función, se efectúa una copia de la
evaluación de
los parámetros reales, que se almacena en una variable local con
el
mismo nombre que el parámetro formal, dentro del registro de
activación. Esto implica que al finalizar la ejecución,
estos
parámetros se destruyen, y los parámetros reales no se ven
afectados.
Es el mecanismo más
genérico de
los lenguajes de programación y en la mayoría de los
cuales no es
necesario especificar ningún modificador del parámetro
formal. El
parámetro real puede ser cualquier expresión.
1.10.4Paso de parámetros por referencia
En el paso de parámetros por
referencia, en vez de trabajar con una copia de los parámetros
reales almacenada en la pila de ejecución, se trabaja
directamente
sobre el parámetro real (en realidad, se utiliza una
indirección
del mismo), por lo que cualquier modificación realizada sobre el
parámetro formal es repercutida automáticamente en el
parámetro
real.
Para ello se usa el concepto
mencionado antes de indireción, es decir, el compilador hace que
los
parámetros formales declarados en la función o
procedimiento
apunten a la misma dirección de memoria que los parámetros
reales.
Este mecanismo de paso de
parámetros
se usa para parámetros de salida y entrada/salida, por lo que el
parámetro real debe ser una variable.
Muchas veces este tipo de paso de
parámetros, combinado con restricciones de solo lectura, se
emplea
en algunos lenguajes de programación para sustituir al
ineficiente
paso de parámetros por valor en pasos de entrada. Nótese
que si se
pasara un vector por valor, se estaría copiando todo su
contenido.
2Programación modular
Una
vez que los programas se fueron haciendo todavía más
complejos y,
por lo tanto, mayores, aún fue necesario crear un nivel
más de
división. Así, ahora era necesario organizar todos
los
procedimientos y funciones de alguna forma. Los módulos
agrupan,
precisamente, procedimentos y funciones afines, y también
los datos
que manipulan, de manera que aquellos que no son empleados por el
resto de módulos quedan ocultos la ellos. Modula-2
(desarrollado a finales de los 70, también por Niklaus
Wirth, es el
sucesor
directo
de Pascal) es un buen ejemplo de lenguaje de programación
basado en módulos.Otro lenguaje que la soporta es Ada.
La meta de la programación modular
es obtener una organización de la arquitectura del software, con
un
diseño no orientado a la simple obtención del programa
final, sino
también a su mantenimiento, a su reutilización y a poder
probarlo y
entenderlo de forma fácil.
Para ello, los algoritmos complejos
y los programas se estructuran en módulos y éstos se
estructuran en
funciones y procedimientos. Al fin y al cabo, recordemos que las
funciones y procedimientos, son porciones de código
diseñadas para
realizar tareas muy específicas.
Los módulos deben agrupar
funcionalidades del software a desarrollar, de tal forma que, en el
desarrollo de una aplicación de hoja de cálculo, por poner
un
ejemplo, todo el manejo de operaciones matemáticas resida en
mismo
módulo. También todas las funciones que tienen que ver con
el
manejo de fórmulas definidas por el usuario, deben estar en otro
módulo aparte (que probablemente necesite el módulo de
matemáticas
para funcionar), y así sucesivamente. El objetivo final
sería poder
reutilizar estos módulos en otras aplicaciones.
La programación modular persigue
que cada módulo y función o procedimiento, cumpla las
siguientes
características:
-
Pequeño tamaño: de esta
forma el impacto de un cambio puede ser perfectamente aislado.
-
Independencia modular: cuanto mayor es
la independencia de los módulos y los procedimientos y
funciones, más sencillo es trabajar con él. El
diseño debe reducir la necesidad de compartir ficheros,
datos, dispositivos y llamadas desde o hacia otros módulos y
procedimientos y funciones.
-
Características de caja negra:
visión exclusiva de la funcionalidad de un módulo o
procedimiento/función en base a sus entradas y salidas sin
tener en cuenta como se realiza el proceso.
-
Modelo conceptual: un diseño es
más fácil de mantener si el modelo de diseño
empleado se ha basado en conceptos lógicos de
organización, los cuales sean más familiares y
comprensibles para el personal de mantenimiento.
-
A
islamiento de los detalles (encapsulación): en un sistema
existen partes que reflejan la filosofía y otras que reflejan
los detalles. Ambas partes deben diseñarse por separado para
evitar que una variación en los detalles afecte a la
filosofía del sistema.
Para conseguir los objetivos
marcados se necesitan estrategias de diseño. Una de las
principales
se basa en la disposición de tareas, es decir, descomponer una
tarea
en otras más sencillas que se hayan identificando en la tarea de
partida.
Una vez descompuesto el software en
tareas, normalmente cada una de ellas será un procedimiento.
Estos
procedimientos se agruparán en módulos distintos,
conformando
grupos que representen las distintas categorías basadas en el
tipo
de problema que resuelven conceptualmente.
La descomposición en tareas
persigue la reducción del tamaño de los procedimientos
hasta
conseguir un sistema más fácil de entender y modificar,
minimizando
la duplicidad del código, así como la creación de
módulos y
procedimientos o funciones útiles y reutilizables. De hecho, si
se
desarrolla un módulo con varios procedimientos y funciones para,
por
ejemplo, funciones matemáticas, este podrá ser reutilizado
en
aplicaciones futuras.
Para medir la calidad de un diseño
modular se emplean las medidas de cohesión y acoplamiento que se
pueden aplicar sobre módulos y procedimientos o funciones.
-
Cohesión: es la medida
de la fuerza o relación funcional de los elementos de un
módulo (entendiendo por elementos, los procedimientos o
funciones que lo componen, las definiciones de los datos y las
llamadas a otros módulos). Un módulo coherente se
encarga de una tarea relativamente sencilla en un programa y
requiere de poca interacción con el resto de módulos
y/o procedimientos y funciones. Por ejemplo, en un módulo de
matemáticas, las funciones contenidas deben estar todas
relacionadas con cálculos matemáticos, exclusivamente.
-
Acoplamiento: grado de
interdependencia entre los distintos módulos. En general, dos
módulos no deben compartir estructuras de datos o variables.
Por otro lado, cada módulo debe definir las funciones y
procedimientos, estructuras de datos y variables que le resulten
necesarias para la realización de su función
específica. Así, el módulo de
matemáticas ya comentado no debe necesitar en absoluto de
otros módulos para trabajar. Otros módulos más
complejos pueden necesitar a su vez de módulos que le sirvan
para proveer de más funcionalidad, pero siempre de la manera
más independiente posible.
Como ya se ha establecido, con
respecto a las funciones y procedimientos, cada uno de ellos debe
depender exclusivamente de los parámetros que intercambia con las
demás procedimientos y funciones.
Mejorar la calidad implica aumentar
la cohesión y disminuir el acoplamiento, debido a las siguientes
razones:
-
Cuantas menos conexiones existan entre
los módulos, menos oportunidades habrá de que el
efecto de un módulo sea contraproducente para otro.
-
Si se desea tener la posibilidad de
cambiar un módulo por otro (con la misma funcionalidad) con
el mínimo riesgo, es decir, que el cambio afecte lo menos
posible a otros módulos entonces el acoplamiento debe ser
mínimo y la cohesión máxima.
-
Mientras se está manteniendo un
módulo, es deseable que no sea necesario preocuparse en los
detalles internos de otros módulos.
2.1Módulos de mayor nivel
Los lenguajes de programación
actuales permiten la creación de módulos y procedimientos
o
funciones. Modula-2 (sucesor de Pascal), fue el primero en soportar
los módulos completamente usando unidades de compilación
independiente, conocidas como Module
(estas encontrarían su lugar en Turbo Pascal de Borland, como
Units). Estos
módulos se componen de funciones o procedimientos que
permiten la realización de tareas específicas.
Se pueden entender los módulos,
que
agrupan procedimientos y funciones con características comunes,
como
de mayor nivel con respecto a las funciones y procedimientos, que
agrupan instrucciones que realizan algún cálculo o cuya
composición
resuelve un determinado problema.
Una vez identificadas las tareas
necesarias para resolver un problema, estas se agrupan en módulos
según criterios como los datos con los que operan, si sirven para
manejar un dispositivo específico, o tienen una emática
común,
etc. Es decir, se agrupan por funcionalidad.
En pseudocódigo los módulos
pueden
representarse empleando la siguiente sintaxis:
MODULO nombreDelModulo
INTERFAZ
USA modulo1,
modulo2,...modulon
CONSTANTES
constante1 : Tipo1
= valorc1
....
TIPOS
Tipo1=def1
...
VARIABLES
variable1: tipo1
....
FUNCION fn1(...) : ...
PROCEDIMIENTO proc1(...)
IMPLEMENTACIÓN
USA modulo1,
modulo2,...modulon;
CONSTANTES
constante1
: Tipo1
= valorc1
....
TIPOS
tipo1=def1
...
VARIABLES
variable1: tipo1
....
FUNCION
fn1(...) : ...
INICIO
...
FIN_FUNCION
PROCEDIMIENTO proc1(...)
INICIO
....
FIN_PROCEDIMIENTO
PROCEDIMIENTO procAux(...) {
proc. Privado }
INICIO
....
FIN_PROCEDIMIENTO
INICIALIZACIÓN
instrucción1
....
instrucciónn
FIN_MODULO
Estos módulos de alto nivel pueden
ser reutilizados totalmente y, por lo tanto, constituyen una buena
forma para poder diseñar software.
Los módulos se soportan de manera
distinta en cada lenguaje de programación, como Ada o el ya
mencionado Modula-2. En C y C++, incluso es necesario separar cada
módulo en dos archivos: un archivo con extensión .h,
que
almacena la parte de interfaz (pública), y otro con
extensión .cpp,
que almacena la parte de implementación (privada). En jC,
por
otro lado, sólo es necesario indicar public
(función pública
o de interfaz y private (función privada o de
implementación)
delante de cada función del módulo. Así, un
módulo es como un
programa en jC, a excepción de que no existe la función main().
3Traducción de pseudocódigo a jC
Aunque se han visto ya algunos
ejemplos, se profundizará en esta sección acerca de la
traducción
de la programación modular a jC.
3.1Paso por valor y paso por referencia en jC
3.1.1Paso por valor
El paso por valor es el
más sencillo de utilizar, sirve para asegurar que el valor pasado
no
va a ser modificado en la función llamadora. Es decir, la
función
llamada puede hacer los cambios que desee en la variable, pero dichos
cambios no se reflejan.
int
sqr(int
x)
{
return
x * x;
}
int
main()
{
print(
“El cuadrado de 2 es “ );
println(
sqr( 2 ) );
}
3.1.2Paso por referencia
En jC, el paso
por referencia no se denota de ninguna manera especial, y de hecho,
está restringida a los tipos complejos, como los vectores y
matrices. En concreto, para los tipos simples: int, double,
char, y bool, no es posible realizar paso por
referencia.
void
sumar1(int
x[])
{
for(int
i = 0; i < size( x ); ++i) {
x[
i ] += 1;
}
}
int
main()
{
int[]
x = new int[5]{ 0, 0, 0, 0, 0 };
sumar1(
x );
for(int
a: x) {
print(
a );
print(
' ' );
}
println();
}
Al
ejecutar el programa anterior, el resultado es una secuencial de
cinco unos.
3.2Funciones y procedimientos
Hay trozos de
código
que se espera que se vayan a necesitar en varias ocasiones, por su
utilidad. En lugar de repetirlo una y otra vez, es posible crear una
función o procedimiento que lo abarque. Estas funciones y
procedimientos pueden recibir datos en forma de parámetros, que
se
denominan formales en la propia función o procedimiento, (ya que
determinan el tipo del dato a recibir), y reales en el momento de la
llamada.
La diferencia entre
función y procedimiento estriba, respectivamente, en si se
retorna
un valor o no.
Existen tres
modificadores posibles para un parámetro en pseudocódigo:
E
(parámetro de entrada), S (parámetro de salida), y
E/S
(parámetro de entrada y salida).
A continuación, un ejemplo de
procedimientos con parámetros de salida:
procedimiento
leerVector(S
v: Vector; S
numElementos: Entero);
//
Los parámetros de Salida pueden ser retornados
int
leerVector(Vector v);
Los parámetros de entrada se
indican normalmente; no existe diferencia alguna entre una
parámetro
de entrada y otro de salida o entrada salida. En este caso, el vector
se está pasando por referencia, y esto se conoce porque es un
vector, es decir, no es un tipo simple. Dado que se desean pasar dos
parámetros como de salida, y uno de ellos es un tipo simple que
no
puede ser pasado por referencia, es necesario devolverlo,
transformando entonces lo que se había planteado inicialmente
como
procedimiento en una función.
procedimiento
escribirVector(E
v: Vector, E
numElementos: Entero);
//
Parámetros de entrada y salida o E/S no se distinguen como tal
void
escribirVector(double[] v, int numElementos);
Aquí el procedimiento se mantiene
como tal, dado que ambos parámetros son de entrada. Sin embargo,
no
se puede especificar tal cosa en jC. Además, el
número de
elementos sí se pasa por valor, aunque debe notarse que en jC
puede
obtenerse el tamaño total del vector mediante size( v ),
lo
cual, según el uso que se le desee dar a dicha función
puede hacer
que el segundo parámetro pueda llegar a ser omitido.
Un ejemplo del mismo concepto con
una función:
función
calcularMedia(E
v: Vector; E n: Entero):
Real;
//
Parámetros de entrada pasan a ser const
double
calcularMedia(double[] v, int numElementos);
En cuanto a los parámetros de E/S,
son el ejemplo típico del paso por referencia, sin revestir mayor
dificultad.
procedimiento
insertar(E/S v: Vector; E pos: Entero;
E e: double);
/*
Parámetros de Entrada/Salida pasan a ser parámetros
pasados por referencia */
void
insertar(double[] v, int pos, double e);
3.3Manejo de
módulos
Los módulos
permiten
reunir funciones y procedimientos en una sola entidad. Normalmente,
se eligen aquellas funciones y procedimientos que comparten la misma
o una finalidad parecida (alta cohesión), y a la vez se espera
que
ese módulo pueda trabajar de manera independiente, es decir, que
no
precise entidades del resto del programa.
|
Pseudocódigo
|
jC
|
|
MODULO
nombreModulo;
USA
modulo1,
modulo2;
INTERFAZ
PROCEDIMIENTO f();
IMPLEMENTACIÓN
PROCEDIMIENTO f()
{ más cosas... }
FIN_PROCEDIMIENTO
PROCEDIMIENTO g()
{ más cosas... }
FIN_PROCEDIMIENTO
|
/**
@name nombremodulo */
import
modulo1;
import
modulo2;
//
INTERFAZ
public
void f()
{
//
más cosas...
}
//
IMPLEMENTACIÓN
private
void g()
{
//
más cosas...
}
|
En el lenguaje de
programación jC simplemente las funciones se marcan con
la
palabra reservada public (es decir, visibles desde otros
módulos o desde un programa) o private
(sólo se pueden usar desde el propio módulo), no
es
necesario realizar una declaración previa de aquellas funciones
que
serán públicas, al contrario que en el
pseudocódigo. Así mismo,
las constantes también pueden ser marcadas como public o
private.
4Ejercicio
resuelto
-
Se muestra un ejemplo a
continuación, con una librería de funciones
estadísticas. El objetivo es crear un programa que, dada una
serie de valores, los guarde en un vector, calculando la media y la
desviación típica. Dado que en este problema se tratan
funcionalidades (como la media y la desviación típica)
que es bastante posible que se vuelvan a utilizar en un futuro,
dichas funcionalidades se decide colocarlas en un módulo
aparte, que podrá ser reutilizado en el futuro.
MODULO UtilesEstadísticos
INTERFAZ
CONSTANTES
MaxVector
: ENTERO = 10000;
TIPOS
Vector =
vector [MaxVector] de REAL
{v: vector de entrada
numElem:
número
de elementos en el vector}
FUNCION calcularMedia(E v: Vector,
E
numElem: ENTERO): REAL
FUNCION calcularDesvTipica(E
v:
Vector, E numElem: ENTERO):
REAL
PROCEDIMIENTO
leerVector (S v:
Vector, S numElem:
ENTERO)
PROCEDIMIENTO
escribirVector(E v:
Vector, E numElem:
ENTERO)
IMPLEMENTACIÓN
FUNCION calcularMedia(E v: Vector,
E
numElem: ENTERO): REAL
VARIABLES
i:
ENTERO
suma:
REAL
INICIO
suma ←
0
DESDE
i ←
0 HASTA numElem – 1
suma ←
suma + v[ i ]
FIN_DESDE
calcularMedia
← suma
/ numElem
FIN_FUNCION
FUNCION calcularDesvTipica(E
v:
Vector, E numElem: ENTERO):
REAL
VARIABLES
i:
ENTERO
media:
REAL
sumaDiferencias:
REAL
INICIO
sumaDiferencia
←
0
media ←
calcularMedia( v, numElem )
DESDE
i ←
0 HASTA numElem – 1
sumaDiferencia
←
abs( v[ i ] - media )
FIN_DESDE
calcularDesvTipica ←
sumaDiferencia / numElem
FIN_FUNCION
PROCEDIMIENTO leerVector (S
v: Vector, S numElem:
ENTERO)
VARIABLES
i: ENTERO
INICIO
{ Leer el número máximo de
elementos }
REPETIR
LEER( numElem )
HASTA ( numElem > 0 Y
numElem < MaxVector )
{ Leer los elementos del vector }
DESDE i ←
0 HASTA n - 1 HACER
LEER ( v[ i ] )
FIN_DESDE
FIN_PROCEDIMIENTO
PROCEDIMIENTO escribirVector(E
v: Vector, E numElem: ENTERO)
VARIABLES
i: ENTERO
INICIO
DESDE i ←
0 HASTA numElem - 1
ESCRIBIR( v[ i ] );
FIN_DESDE
FIN_PROCEDIMIENTO
Un algoritmo que hiciera uso del
módulo anterior sería el siguiente.
ALGORITMO MediaYdesviacion
USA
UtilesEstadísticos
VARIABLES
v:
Vector
numElem:
ENTERO
INICIO
leerVector( v, numElem );
ESCRIBIR( “La media es “,
calcularMedia( v, numElem ) )
ESCRIBIR( “La desviación típica es
“
)
ESCRIBIR( calcularDesvTipica( v, numElem )
)
FIN_DESDE
FIN_ALGORITMO
Como se puede apreciar, se puede
emplear toda la parte de interfaz del módulo como si estuviera
definido directamente en el algoritmo.
En jC, el anterior módulo,
y
su uso, podrían implantarse como sigue:
/** @name stat
* @brief Funciones de
estadística
* @author jbgarcia@uvigo.es
*/
import std.util;
import std.string;
import std.math;
/** @brief Calcula la media de un vector
* @param v Un vector de nums.
reales
* @return La media del vector v
*/
public double
calculaMedia(double[] v)
{
double media = 0;
for(double p: v) {
media += p;
}
return ( media / size( v ) );
}
/** @brief Calcula la desv. tipica de un
vector
* @param v Un vector de nums.
reales
* @return La desv. tipica del
vector v
*/
public double
calculaDesvTipica(double[] v)
{
double desvTipica = 0;
double media = calculaMedia( v );
for(double p: v) {
desvTipica += abs( p - media );
}
return ( desvTipica / size( v ) );
}
/** @brief Devuelve el contenido del vector
como una cadena
* @param v El vector a
transformar en una
cadena
* @return Una cadena de
caracteres con el
contenido del vector
*/
public char[]
vectToStr(double[] v)
{
char[] toret = strCopy( "[ "
);
for(double p: v) {
char[] elem = strConcat( dblToStr(
p ), " " );
toret = strConcat( toret, elem );
}
return strConcat( toret, "]" );
}
/** @brief Devuelve el contenido de un
vector tomado por teclado
* @return El vector tomado del
usuario,
como double[]
*/
public double[] leeVector()
{
// Prepara el vector
int numElementos = strToInt(
readln( "Introduzca num. de
elementos: " ) );
double[] toret = new double[
numElementos ];
// Lee el contenido
for(int i = 0; i < size(
toret ); ++i) {
char[] msg = strCopy( "Introduzca
valor para #" );
msg = strConcat( msg, intToStr( i +1 ) );
toret[ i ] = strToDbl( readln( strConcat(
msg, ": " ) ) );
}
return toret;
}
Finalmente, se incluye la
implementación del pequeño algoritmo de prueba de la
librería
/** @name mediadesviada
* @brief Programa que hace uso
del modl.
stat
calcular la media y la desv.
tipica de
un vector
* @author jbgarcia@uvigo.es
*/
import std.io;
import std.util;
import stat;
int main()
{
double[] v = leeVector();
write( "El vector es: " );
writeln( vectToStr( v ) );
write( "La media es: " );
writeln( calculaMedia( v ) );
write( "La desv. tipica es: " );
writeln( calculaDesvTipica( v ) );
return ExitSuccess;
}
5Ejercicios
-
Crea un programa que determine si dos
cadenas pedidas por teclado son palíndromas. Dos cadenas son
palíndromas cuando pueden ser leídas de izquierda a
derecha y viceversa. Crea un módulo de funciones para la
gestión de cadenas, con funciones para cambiar todos los
caracteres de una cadena a mayúsculas (otra función
para cambiarlos a todos a minúsculas), eliminar espacios en
blanco al comienzo y al final (trim()), etc.
-
Añádele una
función más al módulo anterior, llamada split(),
a la que se le pase un carácter y una cadena, y devuelva un
vector de cadenas con cada una de las partes separadas por el
carácter. Crea un programa que pida una cadena por teclado, y
devuelva las partes separadas por un espacio.
-
Ahora que ya conoces el modo de
programar de forma más correcta en jC, utilizando la
función main() (el punto de entrada del programa),
convierte los programas del capítulo anterior para que lo
utilicen.